Artigo
Aprendizagem Automática (Machine Learning)
T02 - Machine Learning
A aprendizagem automática é a ciência de programar computadores para que possam aprender a partir de dados. Podem ser classificados por
- Paradigma de aprendizagem;
- Intuição matemática;
- Tipo de problema que resolvem.
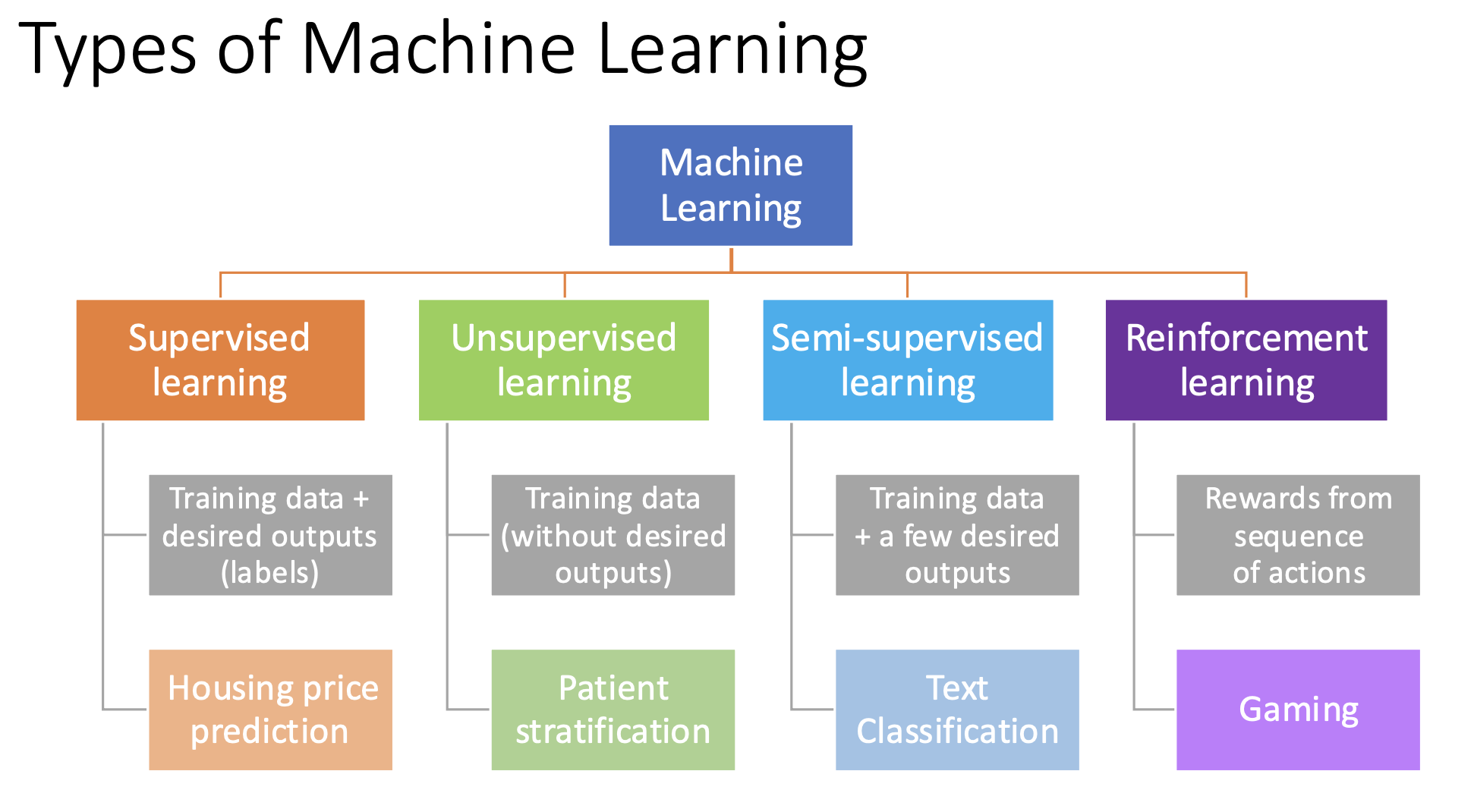
1. Tipos de Modelos de Aprendizagem Automática
1.1. Paradigma de Aprendizagem
- Aprendizagem Supervisionada: Aprende a partir de um conjunto de dados onde as respostas já são conhecidas.
- Identificação de e-mails como spam
- Aprendizagem Não Supervisionada: Dado que não possuem respostas desejadas. O modelo tenta encontrar padrões.
- Estratificação de pacientes / agrupamento de clientes..
- Aprendizagem Semi-supervisionada: Utiliza pequena quantidade de dados que possuem a resposta com uma grande quantidade de dados que não possuem.
- LLM
- Aprendizagem por Reforço: O modelo aprende através de recompensas obtidas.
- Jogos.
1.2. Modelo Baseado na Intuição Principal
Distinguem-se pela lógica interna que processam informação.
- Modelos Geométricos: Utilizam intuição geometrica, como hiperplanos de separação, transformações lineares e métricas de distância.
- Ex.: KNN (K-Nearest Neighbour) e Regressão linear.
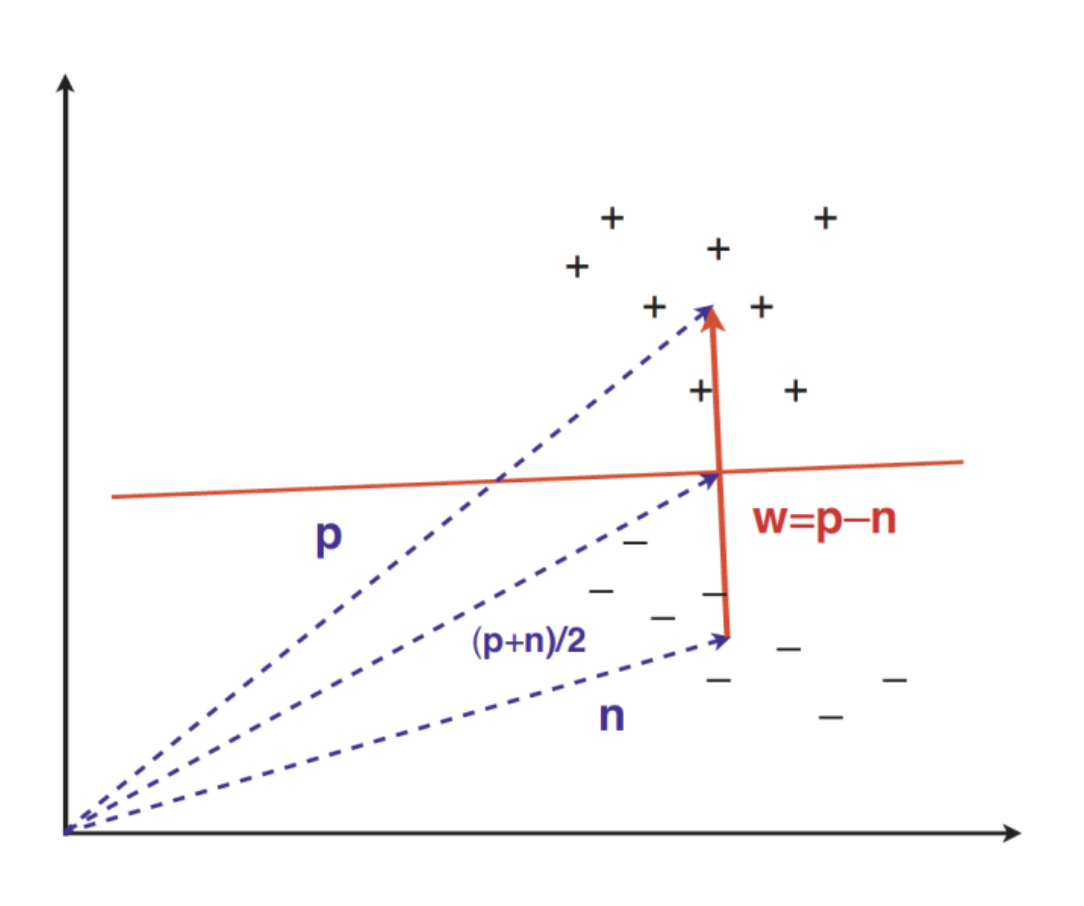
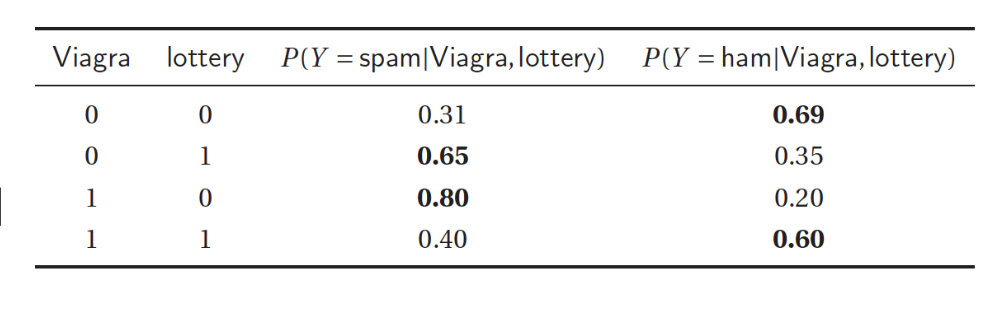
- Modelos Probabilísticos: Encaram aprendizagem como redução de incerteza, utilizando distribuição de probabilidades.
- Ex.: Naïve Bayes
- Modelos Lógicos: São definidos por expressões lógicas que são facilmente interpretáveis pelo ser humano.
-
Ex.: Árvores de Decisão
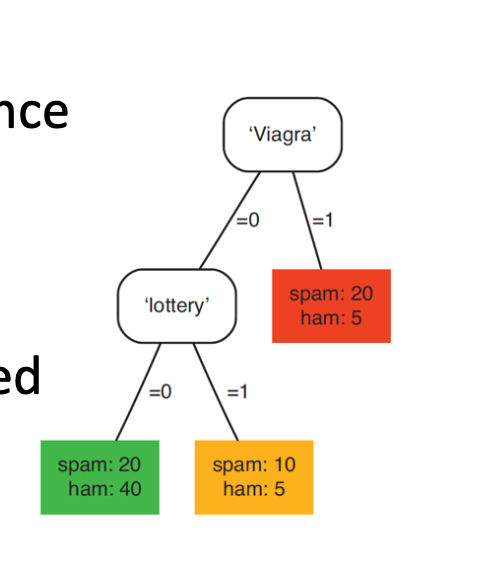
-
1.3. Classificação vs. Regressão
- Classificação: O output é qualitativo ou categórico
- E-mail: spam ou não spam
- Tumor: cancerígeno ou não cancerígeno.
- Regressão: O output é quantitativo ou numérico contínuo
- Prever peso de uma pessoa
- Prever preço de uma casa
2. Introdução à Aprendizagem Supervisionada.
Prever uma saída com base em entradas, utilizando um conjunto de dados para o qual as respostas já são conhecidas. Dividem-se em duas principais categorias:
- Classificação
- Regressão
2.1 Conceitos e Nomenclatura Fundamental.
- Instâncias: objetos de interesse no espaço de dados
- ex.: e-mails individuais.
- Rótulos (Labels): São as respostas desejadas que o modelo deve aprender
- ex.: classificação “spam”
- Conjunto de Treino: Conjunto de instâncias já rotulada, usado para o modelo aprender os padrões
- Conjunto de Teste: Dados rotulado que não foram usados no treino, servindo para avaliar quão bem o modelo se comporta com dados novos.
2.2 Exemplos de Aplicação.
- Saúde: Prever diagnósticos de câncer com base em dados do paciente
- Economia: Estimar crescimento do PIB usando dados políticos e estruturais
- E-commerce: Prever a probabilidade de um cliente comprar algo com base no comportamento de cliques.
2.3. Desafios.
- Complexidade Computacional
- Encontrar o modelo “ótimo” é um problema.
- Quantidade e Qualidade de Dados:
- Tarefas simples exigem milhares de exemplos, enquanto tarefas complexas podem exigir milhões.
- A Maldição da Dimensionalidade:
- Quanto maior o número de dimensões (features) mais difícil se torna encontrar padrões úteis.
- Overfitting vs. Underfitting:
- O overfitting ocorre quando o modelo decora o ruído dos dados de treino e falha em generalizar para novos dados
- O underfitting acontece quando o modelo é simples demais para captar padrões reais.
- Teorema “No-Free-Lunch“:
- Não existe um algoritmo único que seja superior para todos os tipos de problema.
3. Universal Function Approximators (UFA).
Ferramentas de modelagem capaz de aproximar qualquer delineamento de função.
3.1. Objetivo Teórico.
Se as funções de distribuição reais forem conhecidas, deveria ser possível encontrar a separação perfeita entre classes → Optimal Bayes descision boundary.
Para alcançar essa separação ideal, é necessária uma ferramenta de modelagem que seja um aproximador universal.
3.1.1. Entendendo a UFA.
O Modelo Rígido.
Imagine que seja uma régua que não dobra.
- Tenta ligar os pontos, mas como a régua é rígida só consigo desenhar uma linha reta.
- Se os pontos formam curva (como o desenho de uma montanha), a reta vai errar quase todos os pontos.
- Problema: quando tentar “extrapolar” (continuar a linha para fora do papel), o erro será gigante, porque começamos com a ferramenta errada
- Exemplo: Previsão de Vendas de Sorvete. Conforme esquenta, as vendas sobem. Mas, se ficar quente demais (50°C) as pessoas param de sair de casa e as vendas caem. A curva é um arco. Dados: nós só temos dados de dias entre 20°C e 30°C (onde as vendas só estão subindo). Como o Modelo Rígido só faz a linha reta, não cobrimos o caso dos 50°C.
O Aproximador Universal
Ao invés de uma régua (como no modelo rígido) temos um barbante.
3.2. Aplicação em Regressão.
Fazer uma aproximação o mais próxima possível da função real que gerou os dados. Aproximadores Universais não necessários para que a forma da curva gerada possa extrapolar para outras regiões e domínios (como no exemplo de Previsão de Vendas de Sorvete.)
3.3 Aprendizagem a partir de Dados.
São capazes de aprender, a partir dos dados, os parâmetros que caracterizam cada função.
3.4. Diversidade de Modelos.
Muitas ferramentas de aprendizagem supervisionada são aproximadores universais, mas nem todas possuem essa capacidade. O que diferencia as diversas famílias de modelagem é a forma das suas curvas básicas e os procedimentos de ajuste (fitting) utilizados.
4. Conclusão
- Processamento e Compreensão dos Dados: A qualidade e quantidade dos dados são fundamentais. Dados mal coletados podem gerar viés de amostragem ou ruído, prejudicando o modelo
- Avaliação Adequada: Distinguir entre a validação (ajuste de modelo durante o treino) e a avaliação final (teste de eficácia em dados não vistos). O uso de conjunto de testes independentes é essencial para obter um relatório imparcial.
- Expectativas Realistas: O conceito de “melhor modelo” é muitas vezes elusivo, pois depende inteiramente de como os dados são representados e da natureza do problema.
- Preferência pela Simplicidade: Os melhores modelos são os mais simples. Em situações de dúvida, a recomendação é selecionar o modelo disponível mais simples, possuindo menos parâmetros ajustados ou menos combinações de hiperparâmetros.
O foco do especialista não deve estar apenas no algoritmo, mas em todo o pipeline, desde a preparação dos dados até a validação cuidadosa dos resultados.