Artigo
KNN
T03 - K-Nearest Neighbours (KNN)
Algoritmo da “vizinhança” → “Diz-me com quem tu andar e dir-te-ei quem tu és”.
1. Espaços Vetoriais vs. Métricos (Onde os dados “moram”).
1.1 Espaços Vetoriais.
É um espaço de características onde cada instância é descrita por um conjunto de atributos medidos.
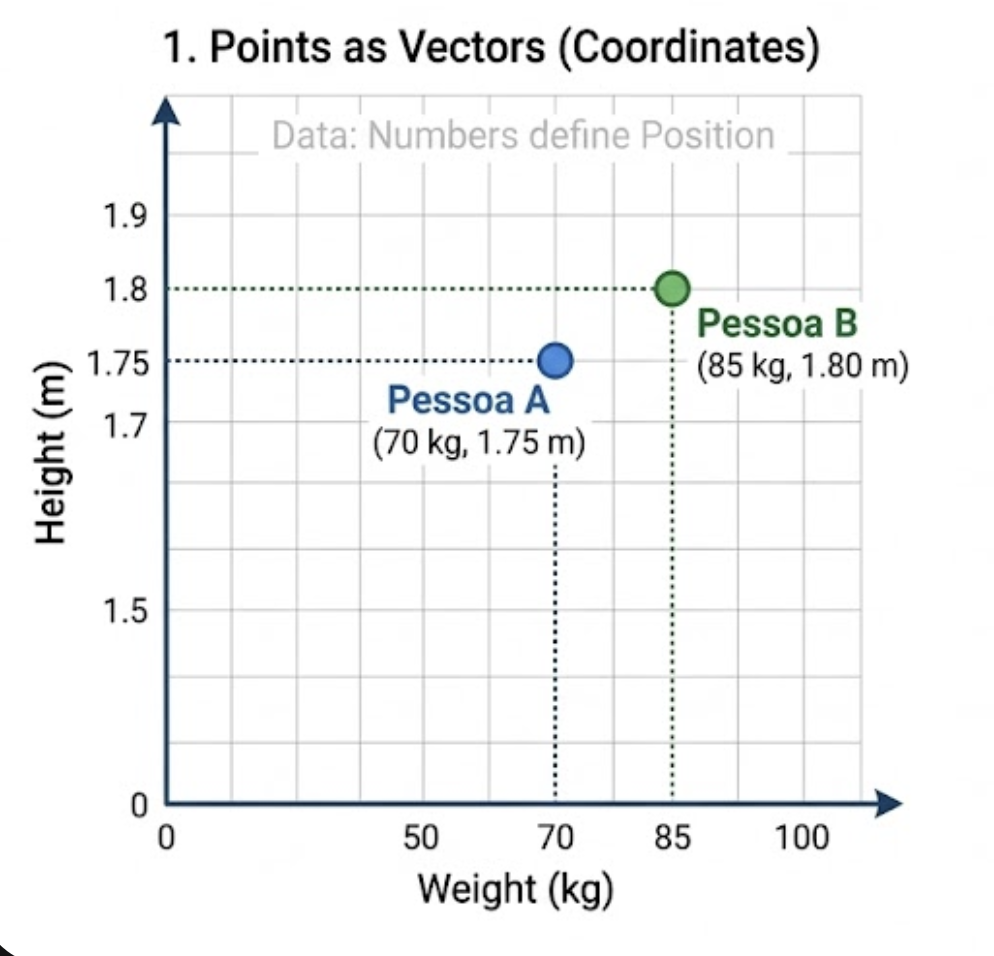
1.1.1 Exemplo:
Imagine que define uma pessoa pelo Peso e pela Altura.
- Pessoa A: (70kg, 1.75m)
- Pessoa B: (85kg, 1.80m)
- Como o KNN vê isso: Coloca esses dois pontos em um gráfico de dois eixos. Para saber a distância, usa uma régua matemática (ex.: Euclidiana) entre os pontos (70, 1.75) e (85, 1.80).
1.2. Espaço Métrico.
As instâncias (dados) são definidos de forma relativa umas às outras. Feito por meio de uma função de distância ou de similaridade.
Em vez de focar apenas nas características isoladas de um objeto, o foco é o quão “perto” ou “longe” ele está de outros objetos no sistema.
- Por que é importante?:
- Nem todos os tipos de dados podem ser transformados em vetores de atributos numéricos (textos, imagens e gráfos). No entanto, mesmo que não possamos descrevê-los como vetores, conseguimos calcular a similaridade ou a distância entre dois textos ou dois gráfos.
2. Métricas de Distância.
Para o KNN funcionar, é preciso medir a proximidade entre os pontos.
2.1. Distância Euclidiana.
O comprimento do segmento de linha reta entre dois pontos.
2.2. Distância de Manhattan.
A soma das diferenças absolutas das coordenadas (comum em grelhas).
2.3. Distância de Minkowski.
Uma generalização das anteriores, onde $p = 1$ resulta em Manhattan e $p = 2$ em Euclidiana.
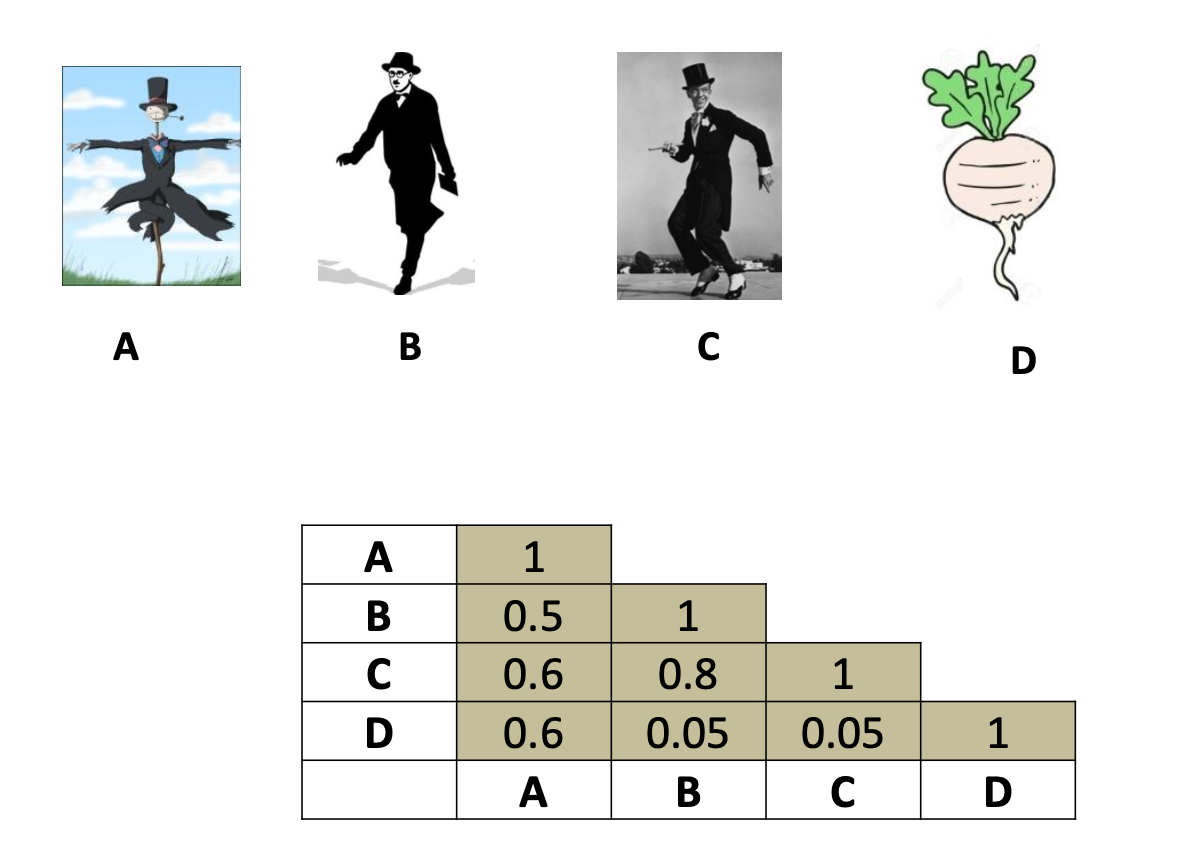
2.4 Atributos Categóricos.
Utilizam-se métricas como Jaccard (razão entre elmentos partilhados e a união), Similaridade de Cosseno (comum em texto) e Distância de Edição.
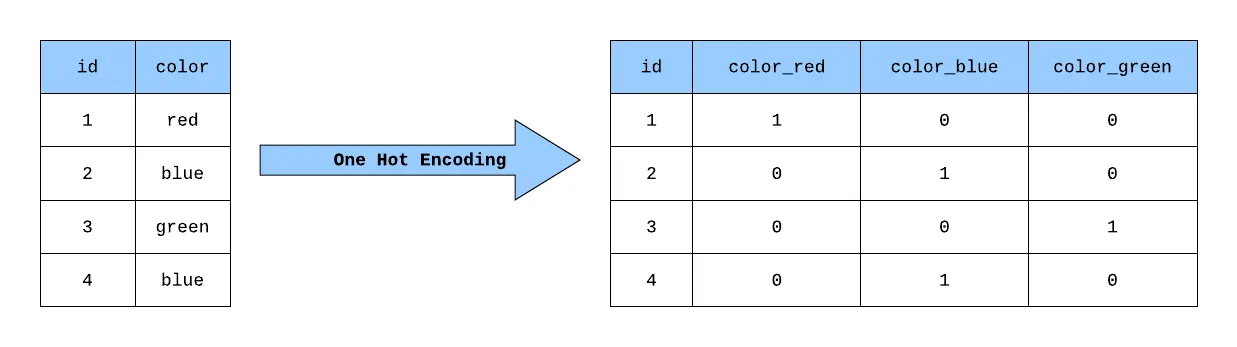
One-Hot Enconding
Convertem os dados em colunas de 0/1 através de um processo chamado One-Hot Enconding, que indica a presença ou ausência de determinada característica.
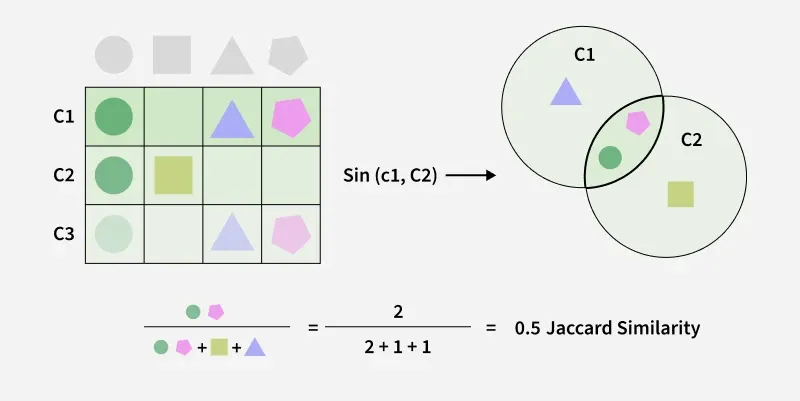
2.4.1. Similaridade de Jaccard.
Mede a similaridade entre 2 conjuntos.
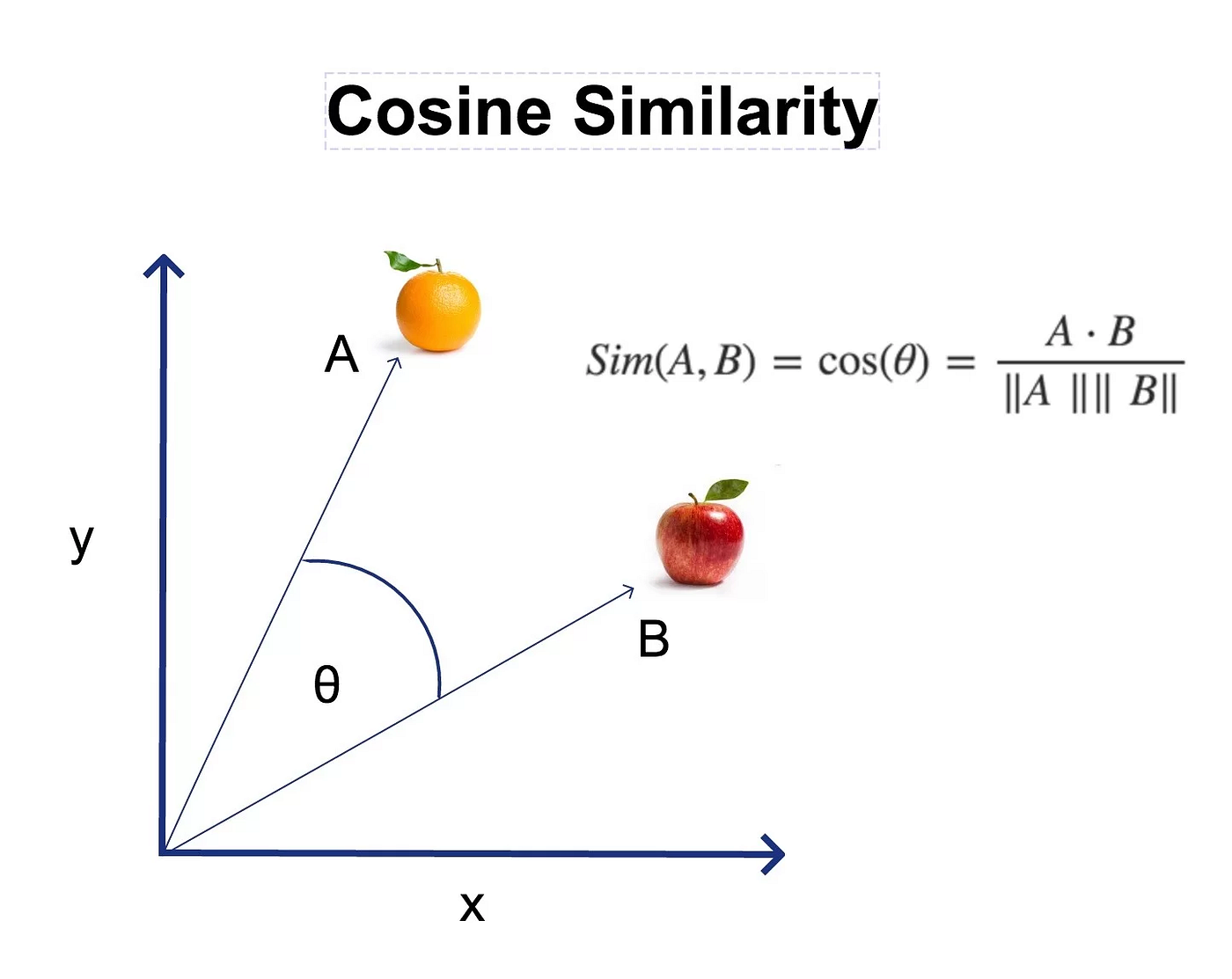
2.4.2. Similaridade de Cosseno.
Mede o ângulo entre dois vetores.
- Livro A: Guia curto de 10 páginas que usa a palavra “receita” 5 vezes
- Livro B: É uma enciclopédia de 500 páginas que usa a palavra “receita” 250 vezes.
Se usar a Distância Euclidiana, o KNN vai dizer que são muito diferentes, porque um é minúsculo e o outro é gigante (os pontos estão longe no mapa).
Se usar a Similaridade de Cosseno, o KNN vai dizer que são quase idênticos. Porque ambos “apontam” para a mesma direção: culinária.
2.4.3. Distância de Levensthein.
Métrica para quando o KNN precisa lidar com dados que não são número, mas sim sequências (como palavras, nomes de clientes, endereços…)
Funciona como um “contador de edições”. → Imagine que tem uma palavra e quer transforma-lá em outra usando o menor número de movimentos possível. É possível Inserir, Deletar e Substituir cada letra.
- “CASAL” para “MASSA”:
- Substitui: C por M → MASAL
- Insere: S → MASSAL
- Deleta: L → MASSA
2.4.4. Distância de Hamming.
Mais rigorosa de que distância de Levenshtein.
Usada para comparações diretas e rígidas. Só funciona se as duas sequências tiverem exatamente o mesmo número de caracteres.
Porta vs Porto → Como só há 1 letra diferente (a última) então a distância de Hamming = 1.
3. Funcionamento do Algoritmo KNN
O KNN funciona em espaços métricos e atribui valores com base na vizinhança de uma nova instância.
- Treino: Não existe treino. Os dados de treino constituem o modelo
- Inferência: Identifica-se os $K$ vizinhos mais próximos segundo uma métrica
- Classificação: A classe mais frequente entre os vizinhos.
- Regressão: A média dos resultados dos vizinhos
4. Ponderação por Distância no KNN
Aplicar peso a diferentes vizinhos.
4.1. Por que usar Ponderação?
Imagine que você quer decidir se vai à praia ($K = 3$).
- Vizinho 1 (a 10 metros de você): Diz que vai chover.
- Vizinho 2 (a 500 metros de você): Diz que vai fazer sol.
- Vizinho 3 (a 600 metros de você): Diz que vai fazer sol
No KNN padrão (sem peso), o sol vence por 2 a 1. Mas o vizinho que está a 10 metros de você tem muito mais chances de estar vendo o mesmo céu que você.
4.2. Distância Inversa ($1/d$).
É a forma mais direta de dar peso. O peso (w) é o inverso da distância (d).
- Se a distância é 2, o peso é $1/2=0.5$.
- Se a distância é 10, o peso é $1/10=0.1$.
4.3. Núcleos Gaussianos.
Aumenta a suavidade se comparada com a distância inversa.
5. Otimizações.
- Paralelização e Distribuição: Muito comum e fácil de paralelizar.
- Algoritmo de Pesquisa Eficiente
- Gestão de Atualizações: Uma vantagem do KNN é ser trivialmente atualizável. Permitindo novos dados sem a necessidade de um novo treino ou ajuste.
6. Conclusões
- Não é simples: o problema de fazer previsões cresce linearmente com o conjunto de dados.
- Rápido de aprender: não existe fase de treino
- Lento a fazer previsões: Para conjuntos de dados grandes, fica lento a fazer previsões.
- É atualizável: Pode adicionar novos dados sem problema ou necessidade de ajuste (reffiting).