Artigo
Árvore de Decisões
T03 - Árvore de Decisão (Tree Models)
1. Conceito Central e Funcionamento.
Estrutura hierárquia de condições onde nós representam atributos, os ramos representam valores desses atributos e as folhas contêm o resultado final ou previsão.
Estes modelos seguem uma estratégia recursiva de “dividir para conquistar”. O objetivo é encontrar o “Best Split” (melhor divisão), selecionando característica que melhor separa as instâncias de acordo com suas classes.
1.1. Exemplo.
O objetivo neste exemplo é ensinar o computador a distinguir entre o que é um golfinho e o que não é um golfinho com base em características físicas.
1. O Problema

Você encontrou vários animais marinhos e quer classificá-los. Para isso, observou quarto características (Features ou atributos).
- Tamanho: O tamanho em metros.
- Guelras: Se o animal tem ou não guelras para respirar debaixo d’água.
- Bico: Se possui um bico proemiente.
- Dentes: Se tem pouco ou muitos dentes
2. Os Dados de Treinamento
Divide os exemplos em dois grupos, que servirão de “gabarito” para o algoritmo:
- Posistive Class (Classe Positiva): São exemplos confirmados de golfinhos. Perceba que todos os exemplos de Positive Class os não golfinhos não possuem guelras.
- Negative Class (Classe Negativa): São animais que não são golfinhos. Note que todos têm Guelras, exceto o n5.
3. Como a Árvore de Decisão “Pensa”
Olhando para esses dados, o aproximador (a árvore) tenta criar uma regra de separação. Por exemplo:
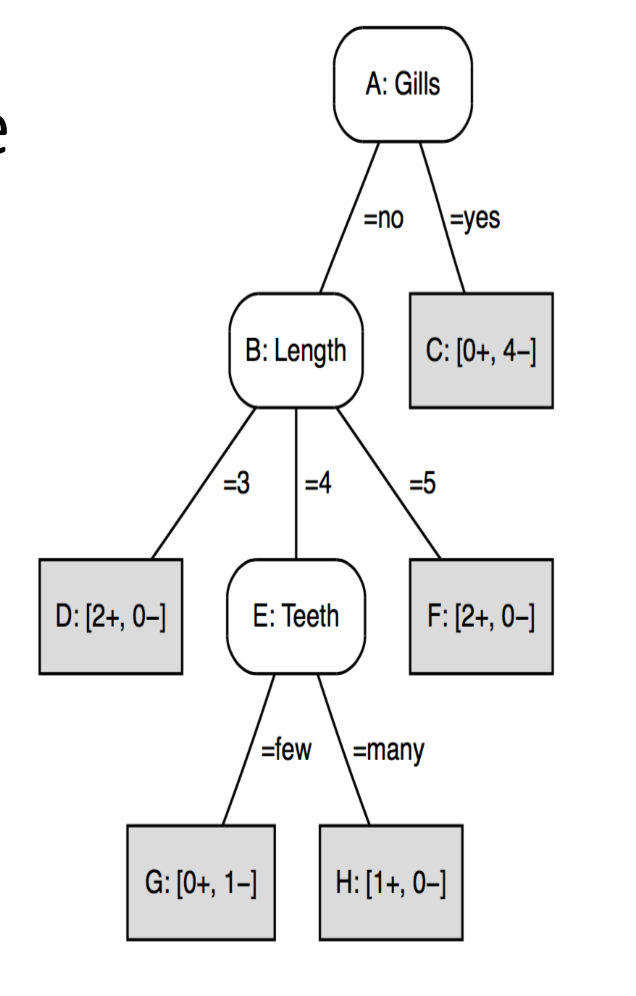
- Primeira pergunta:
O algoritmo olha para todos os dados e percebe que as guelras (Gills) são o divisor de águas.
- A lógica: “Se perguntar sobre guelras, já resolve o problema de quase metade dos animais”
- O resultado: Quem responde “yes” foi jogado para a caixa C que é um “beco sem saída” (folha) onde só existem negativos. Pronto, 4 animais classificados com uma única pergunta
- Segunda pergunta:
Para os animais que sobraram (os que não tem guelras), a árvore ainda tem uma mistura de golfinhos e não-golfinhos. Ela precisa de uma nova peneira
- A lógica: “Entre os que sobraram, o comprimento ajuda a separar?”.
- O resultado:
- Se tem 3m, ela já sabe que é positivo (Caixa D)
- Se tem 5m, ela também já sabe que é positivo (Caixa F).
- O problema: Se tem 4m, ainda está em dúvida (tem um positivo e um negativo sobrando).
- Decisão final:
No nó E (Dentes), a árvore chega no nível de detalhe máximo para não errar nenhum caso.
- A lógica: “Eu tenho dois animais de 4m sem guelras. Como eu os diferencio?”
- O resultado: Olhar para os dentes
- Se tem poucos dentes → Não é golfinho
- Se tem muitos dentes → É golfinho
4. Por que isso é um “Aproximador”?
Essa árvore não criou uma fórmula matemática complexa como ( y = ax + b ). Ela criou uma sequência de regras “Se/Então” (If/Then).
2. Objetivo Principal das Árvores de Decisão.
O principal objetivo é gerar a árvore que constitui o melhor classificador para um determinado problema multidimensional.
O que compõe o objetivo:
- Superação da Complexidade Computacional.
- Alcançar a melhor árvore é um problema extremamente difícil (NP-HARD), pois envolve testar um número exponencialmente grande. Por causa dessa dificuldade, os algoritmos não garantem a árvore ótima, mas utilizam heurística gulosa (greedy) para encontrar soluções eficientes.
- Best Split (Melhor Divisão)
- O sistema seleciona o atributo que melhor separa as amostras de acordo com a sua classe.
- Esse critério é repetido para cada partição gerada até que um critério de paragem seja atingido.
- Minimização da Impureza (Entropia e Gini).
- Um sub-objetivo crítico para que o classificador seja considerado “bom” é a minimização da impureza nos nós resultantes.
- Objetivo em Árvores de Regressão
- O objetivo muda para fazer a aproximação mais próxima possível da função real que gerou os dados.
3. Principais Algoritmos.
- ID3: foca-se em atributos categóricos e não lida com valores em falta.
- CART: Permite tanto classificação como regressão e utiliza divisões binárias.
- C4.5: Lida com atributos contínuos, valores em falta e realiza a poda (pruning) da árvore.
4. Entropia de Shannon
Medidor fundamental utilizada na teoria da informação e na aprendizagem automática para quantificar a incerteza, a desordem ou a impureza de um sistema.
4.1. Definição e Conceito.
A entropia é definida como a medida da informação necessária para descrever um sistema. No contexto de modelos de dados, ela ajuda a determinar quão “misturadas” estão as classes dentro de um conjunto de instâncias.
- Máxima Entropia: Ocorre quando a confusão máxima, ou seja, quando todos os estados possíveis têm probabilidades iguais (ex.: 50% de chance para cada classe numa classificação binária).
- Zero Entropia: Ocorre quando não existe variabilidade. Há apenas um estado possível, o que significa que o sistema está perfeitamente ordenado e não é necessária informação adicional para descrevê-lo.
A soma de todas as probabilidades deve ser igual a 1 ($\sum p_i = 1$).
4.2. Exemplos de Cálculo.
- Moeda Justa (50% caras / 50% coroas): a incerteza é total, resultando numa entropia de 1
- Moeda Viesada (70% caras / 30% coroas): O resultado torna-se mais previsível, o que reduz a entropia para 0,8813
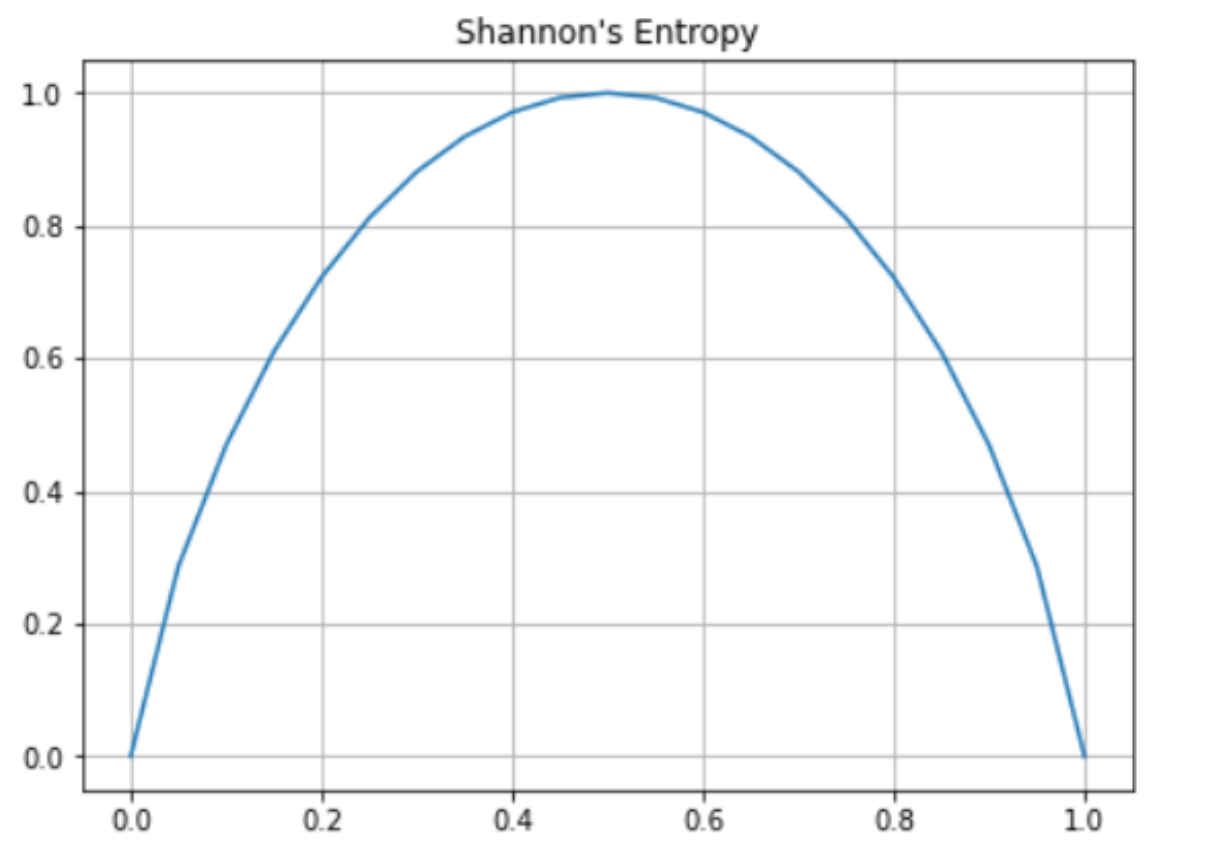
Onde no topo há muita entropia enquanto nas bordas há pouca entropia.
4.3. Aplicação em Árvores de Decisão.
É a principal métrica utilizada por algoritmos como ID3 E C4.5
- Objetivo: Encontrar um critério de divisão (split)que minimize a entropia nos nós restantes.
- Custo da Divisão: O algoritmo calcula o custo de cada partição pesando a entropia de cada novo ramo pela proporção dos dados que ele contém.
- Nós puros: Um nó é considerado “puro” quando a sua entropia é 0. Indicando que todas as instâncias naquele ponto pertencem à mesma classe (por exemplo, todos são “Golfinhos” ou todos são “Não Golfinhos”).
5. Requisitos de uma Medida de Impureza.
Essas são regras fundamentais para garantir que uma métrica (como a Entropia de Shannon ou o Índice de Gini) consiga medir de forma eficaz quão “misturados” ou “puros” estão os dados em um nó de uma árvore de decisão.
- Depende da Magnitude Relativa das Classes: A impureza deve ser calculada na proporção não na quantidade absoluta.
- Não se Alterar Se As Classes Forem Trocadas:
A métrica deve ser simétrica. Isso significa que o valor da impureza deve ser o mesmo se trocar a classe positiva pela negativa.
- Exemplo: Um nó que tem 80% de “Spam” e 20% de “Não Spam” é tão “puro” (ou ordenado) quanto um nó que tem 20% de “Spam” e 80% de “Não Spam”
- Ser 0 Em Pureza Total e Máxima em Confusão Total:
Este requisito define os limites da “escala de desordem” do modelo:
- Pureza Total (Valor = 0):
É o estado de certeza absoluta.
- O que significa: 100% dos animais são golfinhos (ou 100% não são).
- A lógica: Se não mistura, não existe “bagunça”
- Exemplo: Uma caixa que só tem bolas azuis. Se fechar os olhos e pegar uma, tem 100% de certeza que será azul..
- Confusão Máxima (Valor Máximo)
É o estado de caos ou dúvida total.
- O que significa: Exatamente 50% de uma classe e 50% da outra ($p = 0.5$)
- A lógica: É o pior cenário para uma IA. É como jogar uma moeda perfeita: não há pista do que vai acontecer. Por isso, a métrica de “desordem” atinge seu pico aqui.
- Exemplo: Uma caixa com 50 bolas azuis e 50 bolas vermelhas. Sua chance de prever a cor antes de puxar é apenas um palpite (chute).
No gráfico da Entropia de Shannon acima, ilustra perfeitamente essas regras: forma uma parábola que começa em 50 (quando $x = 0$), sobe até o topo em 1 (quando $x = 0.5$) e desce novamente até 0 (quando $x = 1$).
- Pureza Total (Valor = 0):
É o estado de certeza absoluta.
6. Medidas de Classificação
Métricas principais para problemas de classificação:
- Minority Class (Classe Minoritária): Proporção de exemplos que seriam classificados incorretamente se o nó fosse rotulado com base na classe majoritária.
- Ex.: Um ponto da árvore sobraram 10 animais: → 7 são Golfinhos (Classe Majoritária); → 3 são Tubarões (Classe Minoritária); Se a árvore parar de perguntar agora, vai rotular esse nó como “Golfinho”. A Classe Minoritária representa o erro. Então $3/10$ ou 30% é o quão impuro esse nó é.
- Em resumo: Medir a Classe Minoritária é como perguntar: “Se eu decidir agora com base no que tenho mais, quantos exemplos eu vou jogar no lixo por erro?”. Quanto menor esse número, melhor é o seu nó.
- Índice de Gini: Probabilidade de errar a classificação de um item escolhido ao acaso.
- Se o grupo for puro (só golfinhos), a chance de errar é 0.
- Se o grupo for metade/metade, a chance de erro é máxima (0,5 ou 50%).
- Entropia: A quantidade esperada de informação em bits necessária para classificar um exemplo em uma folha.
- Entropia é um medidor de “Dúvida”
- Bit é a unidade básica para resolver uma dúvida de “Sim ou Não”
- Se você tem 50% de chance de ser golfinho e 50% de chance de ser tubarão, você precisa de 1 bit de informação para saber qual é o animal.
- Se 100% dos animais são golfinhos, você precisa de 0 bits, pois já sabe a resposta.
6.1. Gini vs. Entropia
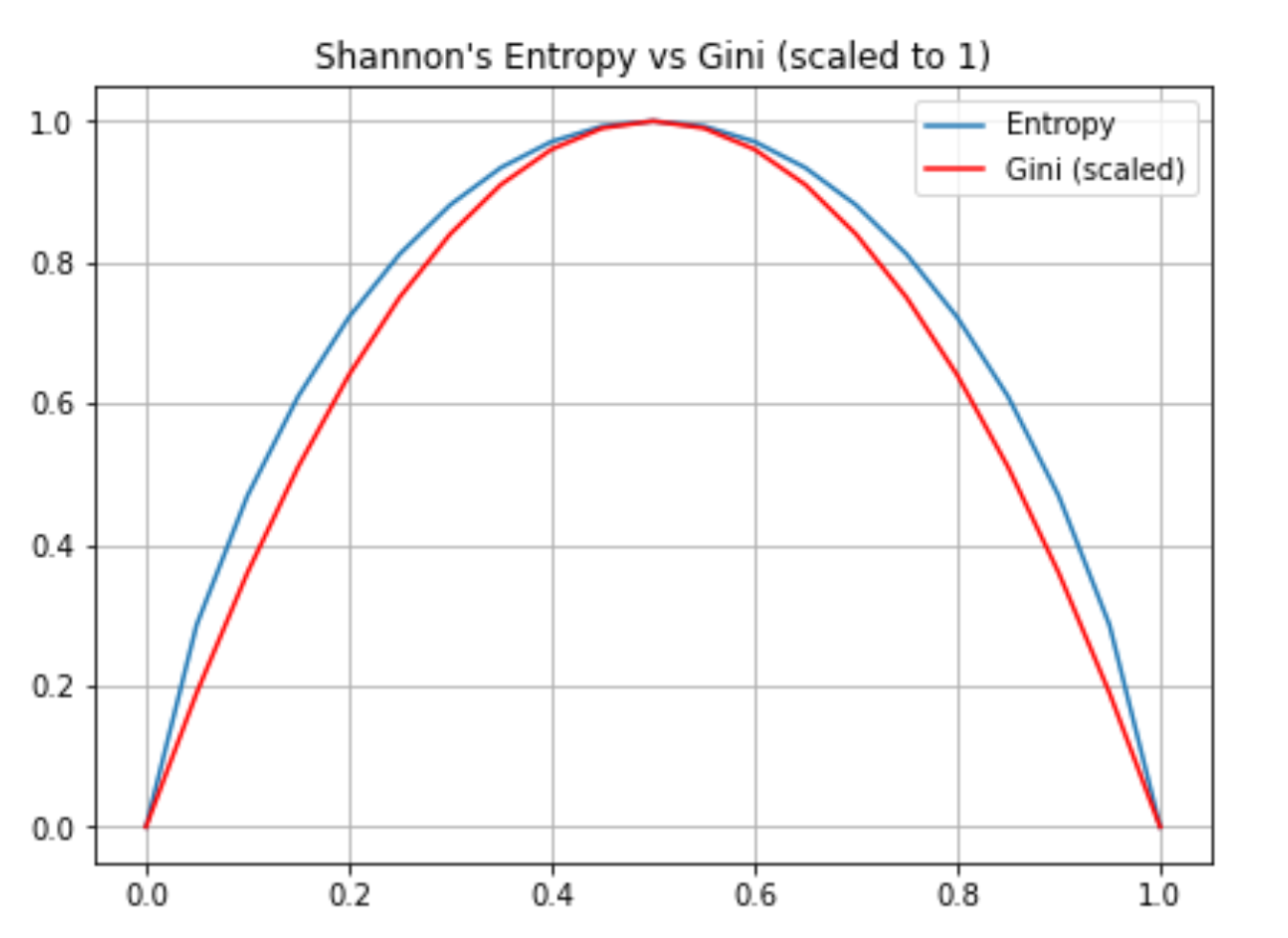
Muito similares porém Entropia é um pouco mais lenta por usar logaritmos.
7. Critérios de Paragem (Stopping Criteria).
Funciona como o “freio de mão” da árvore de decisão.
7.1. Por que precisamos de freios? (O overfitting).
Se não colocar limites, a árvore “decora” os dados de treino em vez de “aprender” o padrão.
- Ex.: Se o animal tem 3,14 metros e nasceu numa terça-feira chuvosa, é um golfinho.
- Para um novo animal, a regra falha. Os critérios de paragem forçam a árvore a ser mais generalista.
8. Splits na Árvore de Decisão.
A possibilidade de um atributo de divisão (”splitting attribute”) aparecer várias vezes numa árvore de decisão depende fundamentalmente de o atributo ser numérico ou categório.
8.1. Atributos Numéricos
-
A princípio pode ser utilizados muitas vezes, mesmo dentro do mesmo ramo da árvore, desde que seja aplicados diferentes pontos de divisão em cada nível
### 8.1.1. Ex.:
Imagine que está tentando adivinhar a idade de alguém usando apenas perguntas de “Sim ou Não”. O atributo é Idade (numérico).
- Pergunta 1 (Raiz): “A idade é maior que 50?” → Sim
- A pessoa tem entre 51 e 100 anos
- Pergunta 2 (Mesmo ramo): “A idade é maior que 80?” → Não
- Agora refinou a busca: a pessoa tem entre 51 e 80 anos.
Pode se repetir pois números são infinitamente divisíveis.
- Pergunta 1 (Raiz): “A idade é maior que 50?” → Sim
8.2. Atributos Categóricos.
Normalmente não aparece mais de uma vez no mesmo ramo, devido:
- Perspectiva da Explicabilidade: Ter atributos categóricos duplicados num único ramo seria redundante e não faria sentido lógico para a interpretação humana.
- Perspectiva Algoritmica: Usar o mesmo atributo novamente resultaria num ganho de informação de zero, uma vez que já não possuí capacidade de discriminar ou fornecer nova informação para a classificação.
8.2.1. Ex.:
Imagine que o atributo é Cor do Cabelo (Categórico: Loiro, Ruivo, Castanho).
- Pergunta 1 (Raiz): “O cabelo é Loiro?” → Sim.
- Todos os suspeitos que sobrarem neste galho SÃO loiros.
- Pergunta 2: Se tentar perguntar novamente no mesmo galho: “O cabelo é loiro?”, a resposta será 100% “Sim” para todo mundo.
- Ganho de informação = Zero.
9. A 1 D Model.
Abordagem de modelação simplificada onde se escolhe uma variável independente para realizar previsões. Unidimensional.
9.1. Processo de Seleção de Variável.
Imagina que quer prever a gravidade da Diabetes em um paciente. Você tem 10 informações (idade, peso, pressão, etc.).
- O Modelo 1D é como um médico que decide olhar apenas para o nível de açúcar no sangue para dar o diagnóstico, ignorando todo o resto
- A lógica do $R^2$: O modelo testa as 10 variáveis, uma por uma, e descobre que a “Variável 2” explica 35% da variação da doença sozinho. É a sua “melhor bússola” individual.
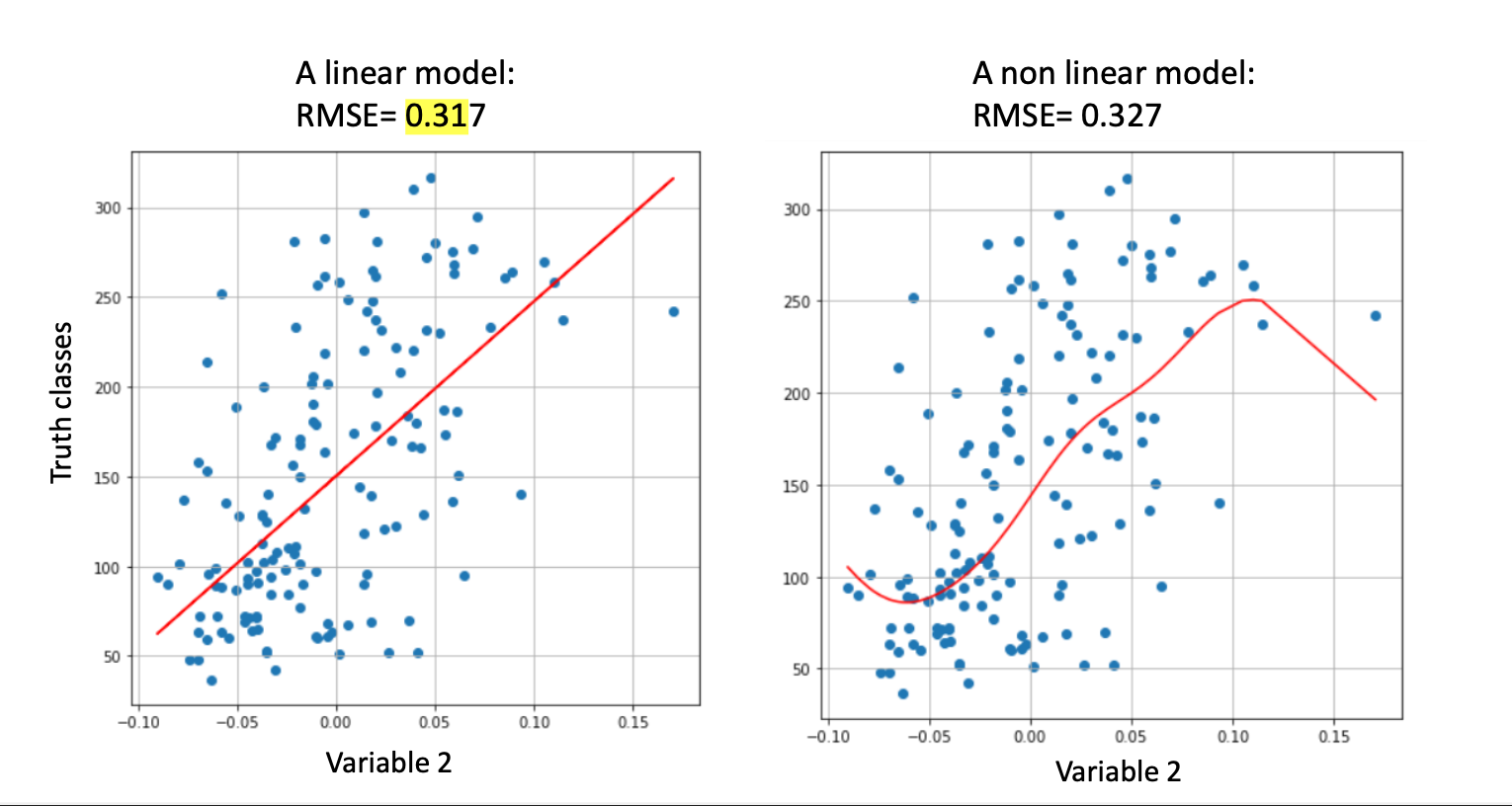
9.2. Modelo 1D vs. Modelo Completo
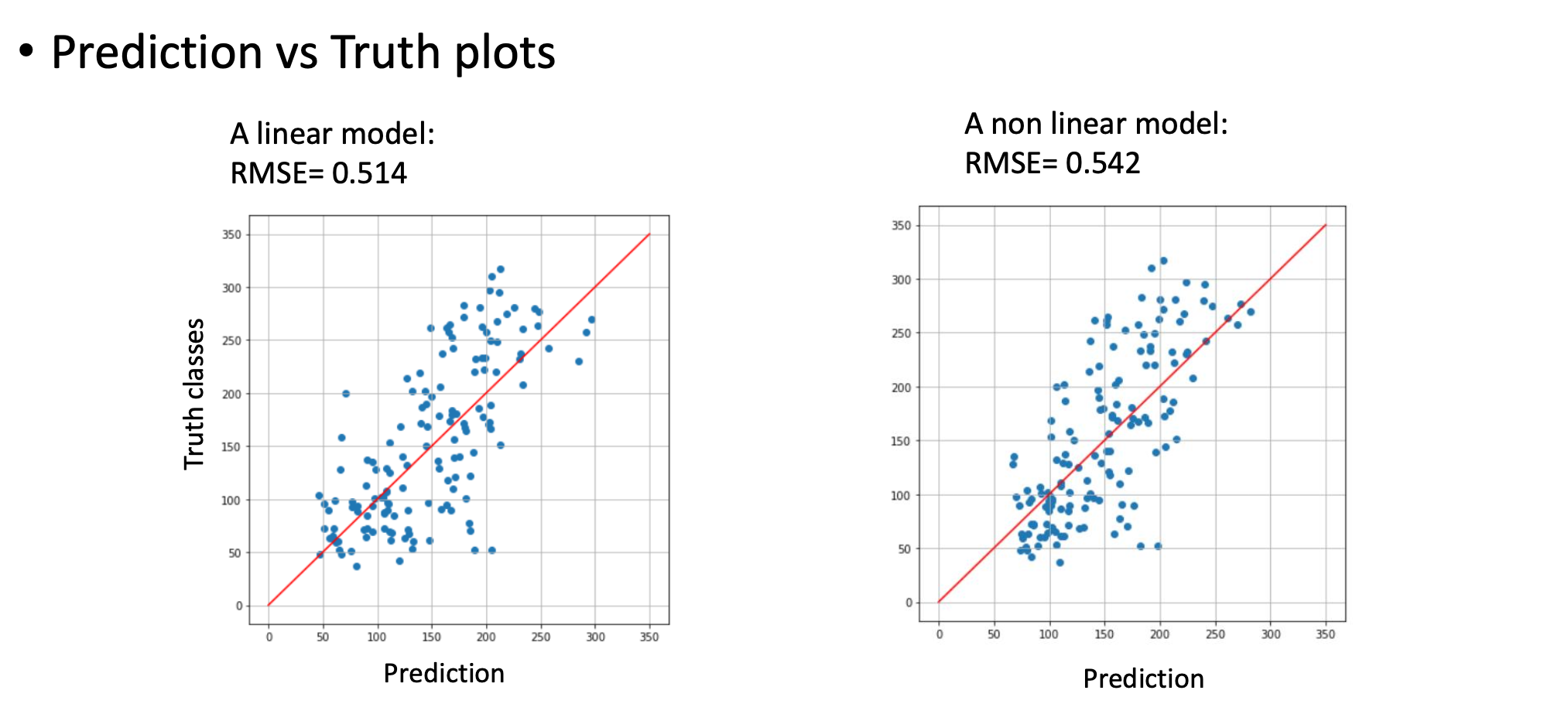
- Modelo 1D: 0,514 (Usando apenas a melhor variável).
- Modelo Completo: 0,542 (Usando as 10 variáveis juntas).
Embora a Variável 2 seja a melhor sozinha, as outras 9 varáveis “carregam” informações que a Variável 2 não tem.
9.3 O “Problema da Dimensionalidade”.
Adicionar variáveis geralmente melhora o modelo, desde que o problema da dimensionalidade seja gerido.
- Se você adicionar variáveis que são apenas “ruído” (tipo a cor favorita do paciente para prever diabetes), o modelo começa a ver padrões onde não existem (Overfitting).
10 Árvores de Regressão com Algoritmo CART.
São uma extensão das árvores de decisão projetadas para prever variáveis numéricas contínuas em vez de classes discretas.
O foco é realizar a melhor aproximação possível da função que gerou os dados.
10.1. Previsão em Degraus
Diferente da linha reta ou curva suave (modelo linear e não linear visto em 9.1), a Árvore de Regressão funciona como uma escada.
- Como pensa: “Para todos os animais com comprimento entre 3m e 4m, eu vou prever que o peso é exatamente 200kg”.
- Visualmente: Se colocar isso num gráfico, não verá uma linha inclinada, mas sim patamares retos. Quanto mais profunda a árvore, mais “degraus” ela tem e mais se parece com uma curva real.
10.2. Métrica de Impureza: O Erro Quadrático Médio (MSE).
Diferente das árvores de classificação, que utilizam Gini ou Entropia, o algoritmo CART para regressão utiliza o Erro Quadrático Médio (MSE) como métrica de impureza para decidir onde dividir os dados.
- O sistema calcula o MSE tanto para o lado direito quanto para o lado esquerdo de um potencial ponto de divisão.
- O objetivo é encontrar o ponto que minimiza a soma desses erros, resultando na maior redução possível da incerteza sobre o valor numérico.
10.3. O Processo de Divisão (Best Split).
O algoritmo opera de forma iterativa e binária:
- Divisão Binária: Apenas divisões em dois ramos.
- Busca Iterativa: Percorre todos os valores possíveis da variável selecionada naquele ramo e escolhe o ponto que minimiza a impureza (MSE).
10.4. Características e Aplicações.
- Resolução Infinita
- Entre 105 e 106, existem infinitos números reais
- Com mais dados e deixar a árvore crescer, pode criar novos degraus e chegar a valores cada vez mais precisos (ex.: 105.22, depois 105.221).
- Entre 105 e 106, existem infinitos números reais
- Complexidade e Ajuste: Como aproximadores universais de funções, estas árvores podem capturar formas complexas e extrapolar padrões para outras regiões de dados.
- Diferente de uma régua rígida que só mede linhas retas, a árvore de decisão é como uma fita métrica flexível: ela consegue contornar cada curva de um gráfico complexo para prever o valor exato, mesmo em situações que nunca aconteceram antes.
- Desempenho: São modelos muito rápidos.
- Overfitting: Por causa da “resolução infinita”, se não usar os critérios de paragem, vai criar um degrau para cada único ponto do gráfico.