Artigo
Pré-processamento de Dados
T04 - Pré-processamento de Dados: Escalonamento e Imputação
O pré-processamento é a “refinaria”: sem ele, o motor (KNN ou árvore) pode engasgar ou dar resultados errados.
1. Escalonamento.
“Colocar todos na mesma régua”.
Imagine que você está comprando casas usando duas variáveis: Número de Quartos (1 a 5) e Preço (100.000 a 1.000.000) Se usar o KNN com esses dados brutos, o preço vai “esmagar” o número de quartos, porque uma diferença de 1 quarto é irrelevante perto de uma diferença de $10.000. O escalonamento resolve isso.
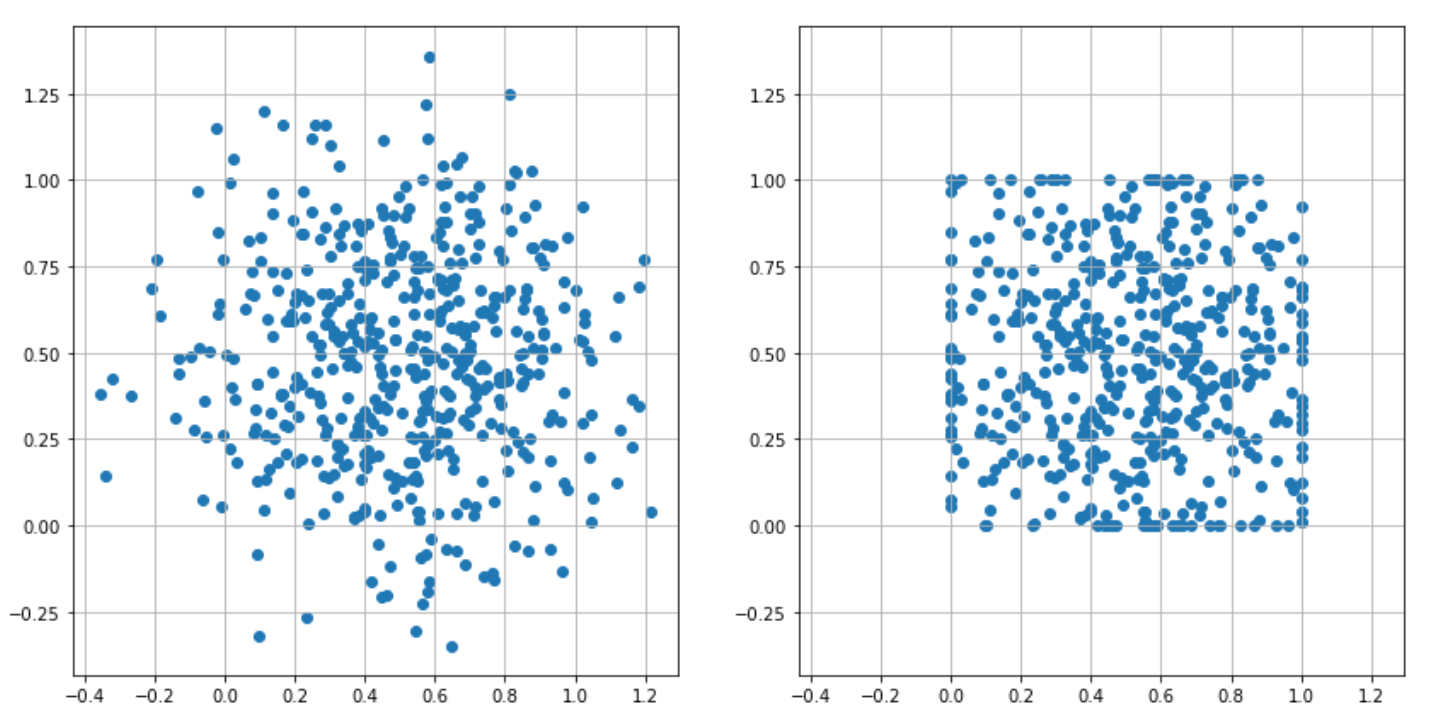
1.1. Range Scaling.
Comprime tudo para um intervalo fixo como [0,1]. Útil para modelos que exigem intervalos específicos.
Outliers são perigosos. → Um bilionário numa lista de salários faria todos os outros parecerem ter $0.
1.2. Standardization Scaling (Z-score).
Transforma os dados para que a média seja 0 e o desvio padrão seja 1.
1.3. Power Transformation.
Transforma dados em uma distribuição normal.
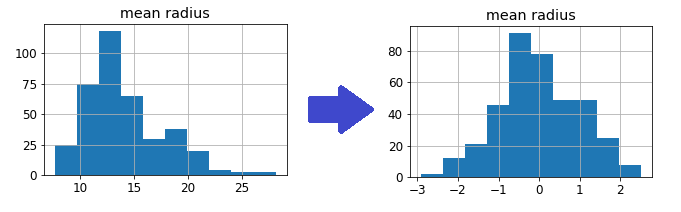
Usar quando:
- Dados estão assimétricos (cauda longa no histograma).
1.4. Unit Norm Scaling.
Desconsidera características (features) individualmente, focando em garantir que cada instância (amostra) tenha norma igual a 1.
Valores no intervalo de 0 e 1.
1.5. Custom Scaling.
- Transformações matemáticas: Ajustar a escala dos dados.
- Linear Clamping: Remove valores extremos ou agrupá-los.
2. Valores em Falta.
O tratamento de Valores em Falta (missing values) é uma etapa crítica que pode ser abordada de quatro formas:
- Não fazer nada
- Eliminar linhas (instâncias): Quando valores em falta forem pequenos
- Eliminar características (colunas): Quando determinada coluna concentram a maioria dos valores ausentes e não são consideradas essenciais.
- Imputar dados.
3. Fundamentos da Imputação.
Refere-se ao processo de preencher lacunas em um conjunto de dados para que ele possa ser utilizado em modelos de aprendizagem automática.
É essencialmente um processo de modelação.
3.1. A Imputação como Parte do Modelo.
- Ajuste no Conjunto de Treino: A imputação deve ser definida e ajustada apenas com os dados de treino.
- Se calcular usando o dataset vai enviesar
- Ordem de Execução: Imputação → Modelo de Inferência
- Preservação de Propriedades: O objetivo fundamental é identificar um valor “bom” para preencher as células vazias, de modo que as propriedades gerais do conjunto de dados não sejam alteradas e o modelo final não seja prejudicado.
4. Métodos de Imputação.
Duas abordagens principais para encontrar os valores.
4.1. Imputação Univariada.
Foca em uma única variável por vez. Substitui o valor em falta por estatísticas como a média, mediana, moda ou um valor constante fixo. É um método simples que funciona bem quando não há muitos dados em falta.
4.2. Imputação KNN.
Suporta multiplas variáveis. Utiliza as instâncias mais próximas (vizinhos) que possuem dados conhecidos para estimar o valor ausenta. Embora mais complexo, pode ser lento se houver muitos dados em falta.
5. A Relação Entre Imputação e Escalonamento.
Normalmente, deve-se realizar o escalonamento de dados antes da imputação.
Imputar dados antes de escalá-los pode alterar as propriedades de cada característica (feature) e atrapalhar a contribuição individual delas para o modelo.
Exceção: O Unit Norm Scaling é uma exceção pois geralmente não permite valores em falta, o que exige que a imputação ou remoção ocorra antes.
6. Considerações Finais.
- Análise Exploratória de Dados: É fundamental que os dados sejam visualizados e inspecionados antes de se ajustar a qualquer modelo.
- Abordagem Personalizada: Deve-se evitar a estratégia de “One Size Fits All”.
- Imagine uma tabela com: Peso (numérico), Cor (categórico) e Renda (numérico com outliers).
- Erro: Aplicar Standardization em tudo.
- Solução: Usar Standardization no Peso, One-Hot Encoding na Cor e Power Transform na Renda. Tratar cada coluna conforme a sua “personalidade” matemática extrai muito mais inteligência dos dados.
- Imagine uma tabela com: Peso (numérico), Cor (categórico) e Renda (numérico com outliers).
- Ordem das Operações: Escalar primeiro, Imputar depois.
- Documentação do Pipeline: Manter todo pipeline de processamento bem documentado.